Pipes and Filters
The Pipes and Filters pattern extends the Pipes and Filters pattern [POSA96, Shaw95, SG96] with aspects of functional parallelism. Each parallel component performs a different step of the computation, following a precise order of operations on ordered data that is passed from one computation stage to another as a flow through the structure.
Examples
A Non-programming Example
Imagine the assembly line of an automobile factory. There are lots of tasks to manufacture a car, but consider only some very general tasks: 1) frame and power chain installation, 2) bolting the body on the frame, 3) mount the engine, and 4) put on the seats and the wheels. Based on this description of tasks, an assembly line is simply a pipeline of tasks, in which the procedure to manufacture a car requires four tasks that can be overlapped in time: while seats and wheels are put on for a car, the engine is being mounted on another, etc. Ideally, consider that each task is designed so that each completes in a cycle of time. After four cycles, seats and wheels are installed for the first car, the engine is mounted on the second car, the body of the third car is bolted, and the chassis of the fourth car is built. However, from the fifth cycle onwards, the manufacture of a new car requires only a cycle of time to be completed, exploiting the parallelism inherent in the ordered tasks.
A Programming Example
In image processing, rendering is a jargon word that has come to mean "the collection of operations necessary to project a view of an object or a scene onto a view surface". The best way to break down the overall rendering process is to consider each object as a different coordinate space, in which independent operations can be carried out simultaneously [Watt93]. The input to a polygonal renderer is a list of polygons and the output is a colour for each pixel on the screen. To build up, for instance, a 3D scene, four general tasks are to be performed per object (Figure 1).
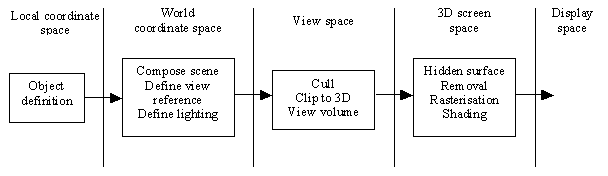
Figure 1. A 3D rendering pipeline.
As in the non-programming example, each one of the tasks can be overlapped in time. In common applications for the film and video industry, the time required to render scene usually can be decreased. The rendering of a special effect scene of 10 seconds using a standard resolution of 2048´1536 pixels takes up to 130 hours of processing time on a single high-end Macintosh or PC platform. Using a parallel approach, with a 16 node CYCORE (a Parsytec parallel machine) this process is reduced to 10.5 hours [HPCN98].
Problem
The application of a series of ordered but independent computations is required, perhaps as a series of time-step operations, on ordered data. Conceptually, a single data object is transformed. If the computations were carried out serially, the output data set of the first operation would serve as input to the operations during the next step, whose output would in turn serve as input to the subsequent step-operations. Generally, performance as execution time is the feature of interest.
Forces
According to the problem description and considering granularity and load balance as other important forces for parallel software design [Fos94, CT92] the following forces should be considered for a parallel version of the Pipes and Filters pattern:
- Maintain the precise order of operations.
- Preserve the order of shared data among all operations.
- Consider the introduction of parallelism, in which different step-operations can process different pieces of data at the same time.
- Distribute process into similar amounts among all step-operation.
- Improvement in performance is achieved when execution time decreases.
Solution
Parallelism is represented by overlapping operations through time. The operations produce data output that depend on preceding operations on its data input, as incrementally ordered steps. Data from different steps are used to generate change of the input over time. The first set of components begins to compute as soon as the first data are available, during the first time-step. When its computation is finished, the result data is passed to another set of components in the second time-step, following the order of the algorithm. Then, while this computation takes place on the data, the first set of components is free to accept more new data. The results from the second time-step components can also be passed forward, to be operated on by a set of components in a third-step, while now the first time-step can accept more new data, and the second time-step operates on the second group of data, and so forth [POSA96, CG88, Shaw95, Pan96].
Structure
This pattern is called Pipes and Filters since data is passed as a flow from one computation stage to another along a pipeline of different processing elements. The key feature is that data results are passed just one way through the structure. The complete parallel execution incrementally builds up, when data becomes available at each stage. Different components simultaneously exist and process during the execution time (Figure 2).
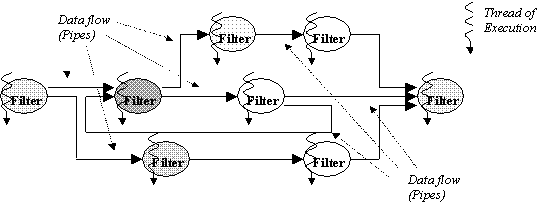
Figure 2. Pipes and Filters pattern.
Participants
- Filter. The responsibilities of a filter component are to generate data or get input data from a pipe, to perform an operation on its local data, and to send output result data to one or several pipes.
- Pipe. The responsibilities of a pipe component are to transfer data between filters, sometimes to buffer data or to synchronise activity between neighbouring filters.
Dynamics
Due to the parallel execution of the components of the pattern, the following typical scenario is proposed to describe its basic run-time behaviour. As all filters and pipes are active simultaneously, they accept data, operate on it in the case of filters, and send it to the next step. Pipes synchronise the activity between filters. This approach is based on the dynamic behaviour exposed by the Pipes and Filters pattern in [POSA96].
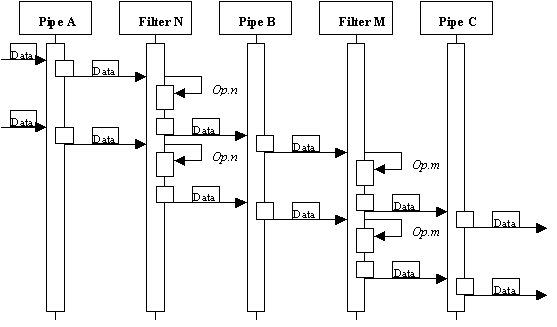
Figure 3. Scenario of Pipes and filters pattern.
In this scenario (figure 3), the following steps are followed:
- Pipe A receives data from a Data Source or another previous filter, synchronising and transferring it to the Filter N.
- Filter N receives the package of data, performs operation Op.n on it, and delivers the results to Pipe B. At the same time, new data arrives to the Pipe A, which delivers it as soon as it can synchronise with Filter N. Pipe B synchronises and transfers the data to Filter M.
- Filter M receives the data, performs Op.m on it, and delivers it to Pipe C, which sends it to the next filter or Data Sink. Simultaneously, Filter N has received the new data, performed Op.n on it, and synchronising with Pipe B to deliver it.
- The previous steps are repeated over and over until no further data is received from the previous Data Source or filter.
Implementation
The implementation process is based on the four stages mentioned above in the Context in general and Implementation in general sections.
- Partitioning. The computation that is to be performed is decomposed, attending the ordered operations to be performed into a sequence of different operation stages, in which orderly data is received, operated on and passed to the next stage. Attention focuses on recognising opportunities for simultaneous execution between subsequent operations, to assign and define potential filter components. Initially, filter components are defined by gathering operation stages, considering characteristics of granularity and load-balance. As each stage represents a transformational relation between input/output data, filters can be composed of a single processing element (for instance, a process, task, function, object, etc.) or a subsystem of processing elements. Design patterns [GHJV95, POSA96, PLoP94, PLoP95] can be useful to implement the latter ones; particularly, consider the Active Object pattern [LS95] and the "Ubiquitous Agent" pattern [JP96].
- Communication. The communication required to coordinate the simultaneous execution of stages is determined, considering communication structures and procedures to define the pipe components. Common characteristics that should be carefully considered are the type and size of the data to be passed, and the synchronous or asynchronous coordination schema, trying to reduce the costs of communication and synchronisation. Usually, a synchronous coordination is commonly used in Pipes and Filters pattern systems. The implementation of pipe components obeys to features of the programming language used. If the programming language has defined the necessary communication structures for the size and type of the data, a pipe in general can be usually defined in terms of a single communicating element (for instance, a process, a stream, a channel, etc.). However, in case that more complexity in data size and type is required, a pipe component can be implemented as a subsystem of elements, using design patterns. Especially, patterns like the Broker pattern [POSA96], the Composite Messages pattern [SC95], and those defined in [CMP95] can help to define and implement pipe components.
- Agglomeration. The filter and pipe structures defined in the previous stages should be evaluated with respect to the performance requirements and implementation costs. Once initial filters are defined, pipes are considered simply to allow data flow between filters. If an initial proposed agglomeration does not accomplish the expected performance, the conjecture-test approach can be used to propose another agglomeration schema. Recombining the operations by replacing pipes between them modifies the granularity and load balance, aiming to balance the workload and to reduce communication costs.
- Mapping. Each component is assigned to a processor, attempting to maximise processor utilisation and minimise communication costs. Usually, mapping is specified as static for Pipes and Filters pattern systems. As a "rule of thumb", these systems may have a good performance when implemented using shared-memory machines, or can be adapted to distributed-memory systems, if the communication network is fast enough to pipe data sets from one filter to the next [Pan96, Pfis95].
Consequences
Benefits
- The use of Pipes and Filters pattern allows the description of a computation in terms of the composition of ordered operations of its component filters. Every operation can be understood then in terms of input/output relations of ordered data [SG96].
- Systems based on the Pipes and Filters pattern support in a natural form parallel execution. Each filter is considered a separate operation that potentially can be executed simultaneously with other filters [SG96].
- If process is distributed into similar amounts, Pipes and Filters systems are relatively easy to enhance and maintain by filter exchange and recombination. For parallel systems, reuse is enhanced as filters and pipes are composed as active components. Flexibility is introduced by the addition of new filters, and replacement of old filters by improved ones. As filters and pipes present a simple interface, it is relatively easy to exchange and recombine them within the same architecture [POSA96, SG96].
- The performance of Pipes and Filters architectures depends mostly on the number of steps to be computed. Once all components are active, the processing efficiency is constant [POSA96, NHST94].
- Pipes and Filters structures permit certain specialised analysis methods relevant to parallel systems, such as throughput and deadlock analysis [SG96].
Liabilities
- The use of Pipes and filters introduces potential execution problems if they are not properly load-balanced; this is, if the stages do not all present a similar execution speed. As faster stages will finish processing before slower ones, the parallel system will be as fast as its slowest stage. A common solution to this problem is to execute slow stages on faster processors, but load balancing can still be quite difficult. Another solution is to modify the mapping of software components to hardware processors, and test each stage to get a similar speed. If it is not possible to balance the work load, performance that could potentially be obtained from a Pipes and Filters system may not be worth the programming effort [Pan96, NHST94].
- Synchronisation is another potential problem of Pipes and Filters systems related with load balance. If each stage causes delay during execution, this delay is spread through all the following filters. Furthermore, if feedback to previous stages is used, the whole system tends to slow down after each operation.
- Granularity of Pipes and Filters systems is usually set medium or coarse. This is due to the efficiency of these systems is based on the supposition that pipe communication is a simple action compared to the filters operation. If the time spent communicating tends to be larger than the time required to operate on the flow of data, the performance of the system decreases.
- Pipes and Filters systems can degenerate to the point where they become a batch sequential system, this is each step processes all data as a single entity. In this case, each stage does not incrementally process a stream of data. To avoid this situation each filter must be designed to provide a complete incremental parallel transformation of input data to output data [SG96].
- The most difficult aspect of Pipes and Filters systems is error handling. An error reporting strategy should at least be defined throughout the system. However, concrete strategies for error recovery or handling depend directly on the problem to solve. Most applications consider that if an error occurs, the system either restarts the pipe, or ignores it. If none of these are possible the use of alternative patterns, such as the Layers pattern [POSA96] is advised.
Known uses
- The butterfly communication structure, used in many parallel systems to obtain the Fast Fourier Transform (FFT), presents a basic Pipes and Filters pattern. Input values are propagated through intermediate stages, where filters perform calculations on data when it is available. The whole computation can be viewed as a flow through crossing pipes that connect filters [Fos94].
- Parallel search algorithms mainly present a Pipes and Filters structure. An example is the parallel implementation of the CYK Algorithm (Cocke, Younger and Kasami), used to answer the membership question: "Given a string and a grammar, is the string member of the language generated by the grammar?" [CG88, NHST94].
- Operations for image processing, like convolution, where two images are passed as streams of data through several filters (FFT, multiplication and inverse FFT) in order to calculate their convolution [Fos94].
Related patterns
The Pipes and Filters pattern for parallel programming is presented as an extension of the original Pipes and Filters pattern [POSA96] and Pipes and Filters architectural style [Shaw95, SG96]. Other patterns that share the similar ordered transformation approach can be found in [PLoP94]; especially consider the Pipe and Filters pattern and the Streams pattern. Another pattern that can be consulted for implementation issues using C++ is the Pipeline Design Pattern [VBT95].
Contact Information
Jorge Luis Ortega Arjona.
E-mail jortega-arjona@acm.org